Einführung in die Softwarearchitekturen
Angestrebtes Ziel einer Architektur ist die Gliederung des Systems in Einheiten mit explizit festgelegten Aufgaben und Abhängigkeiten zwischen diesen Einheiten.
Die Erfassung dieser Abhängigkeiten und Aufgaben erfolgt über die Schnittstellen. Hiermit werden die Einheiten so gekapselt, dass eine verbindliche Regelung besteht, in welcher Form von außen über die Schnittstelle auf eine gekapselte Einheit eingewirkt werden kann.
(1) Entwurfsprinzipien
Beim Entwurf und Implementierung von Softwarearchitekturen hält man sich an grundsätzlichen Entwurfsprinzipien. Diese stellen dabei einen Leitfaden dar, um die unvermeidliche Komplexität moderner Softwaresysteme beherrschbar zu machen und eine unkontrollierte Verflechtung der Komponenten zu verhindern. Erst durch diese methodische Ordnung wird sichergestellt, dass das System über seinen gesamten Lebenszyklus hinweg wartbar, testbar und flexibel gegenüber neuen Anforderungen bleibt.
(1.1) Kapselung und Information Hiding
Kapselung bedeutet, dass der Zugriff auf ein Software-Modul nicht direkt erfolgt, sondern kontrolliert über eine definierte Schnittstelle. Das Innere eines Moduls ist geschützt. Auf interne Daten oder Zustände (die Implementierung) kann von außen nicht direkt zugegriffen werden. Die Schnittstelle definiert genau, was in das Modul hineingeht und was herauskommt.
Information Hiding
Ein zentraler Aspekt der Kapselung ist das Information Hiding (Geheimnisprinzip). Der Nutzer des Moduls muss nur die Schnittstelle kennen (das „Was“). Er muss nicht wissen, wie das Modul intern funktioniert. Der Entwickler des Moduls muss sicherstellen, dass die Schnittstelle bedient wird (das „Wie“). Er kann die interne Umsetzung ändern, solange die Schnittstelle gleich bleibt.
Vorteile
- Klare Architektur: Systeme sind besser strukturiert.
- Wiederverwendbarkeit: Module können leichter in anderen Kontexten genutzt werden.
- Sicherheit: Entwickler können sich auf die Einhaltung der Anforderungen verlassen.
Nachteile
- Höherer Aufwand: Das Design und die Planung der Schnittstellen kosten anfangs mehr Zeit.
- Performance: Die Abstraktion und das Laden passender Implementierungen können (geringe) Leistungseinbußen verursachen.
(1.2) KISS - so komplex wie nötig, so einfach wie möglich
Die Abkürzung KISS (von engl.: Keep it smart and simple) bezeichnet ein Entwurfsprinzip, nach welchem zu einem gegebenen Problem eine einfach gehaltene, leicht verständliche und dennoch tragfähige Lösung entwickelt werden soll. Ziel der angestrebten Vereinfachung ist die Fehler- und Wartungsminimierung.
(1.3) Kopplung und Kohäsion
Kopplung (Coupling) und Kohäsion (Cohesion) bestimmen, wie gut eine Software wartbar, erweiterbar und stabil ist.
In der Softwarearchitektur strebt man fast immer eine lose Kopplung (Low Coupling) und eine hohe Kohäsion (High Cohesion). Die Module (Komponenten/Klassen) sollen untereinander möglichst wenig voneinander wissen (lose Kopplung), aber innerlich sehr fokussiert auf genau eine Aufgabe sein (hohe Kohäsion).
Kopplung (Beziehung zwischen den Modulen)
Kopplung beschreibt, wie stark zwei Module voneinander abhängig sind. Wenn Module stark gekoppelt sind, führt eine Änderung in Modul A oft zu einem Fehler im Modul B (Dominoeffekt). Das Ziel ist es, so wenig Abhängigkeiten zwischen den Modulen zu haben. Ein Modul sollte eigenständig funktionieren.
Je nach Abhängigkeitsgrad, lassen sich unterschiedliche Arten von Kopplung feststellen:
- Pathologische / Inhaltskopplung (Sehr schlecht): Ein Modul greift direkt auf das Innere eines anderen Moduls ein (verletzt die Kapselung).
- Bereichskopplung (Common Environment): Zwei Module teilen sich globale Daten (z. B. globale Variablen). Das ist fehleranfällig.
- Kontrollkopplung: Ein Modul steuert den Ablauf eines anderen (z. B. durch "Flags" oder Steuerparameter). Das aufrufende Modul weiß zu viel darüber, wie das andere arbeitet.
- Datenkopplung (Gut): Module tauschen nur reine Daten (Parameter) aus. Sie wissen nichts voneinander, nur was rein und raus geht.
Kohäsion (Zusammenhalt innerhalb eines Moduls)
Kohäsion beschreibt, wie gut die Teile innerhalb eines einzigen Moduls logisch zusammengehören. Jedes Modul (oder jede Klasse/Komponente) soll genau eine klar definierte Aufgabe haben (Single-Responsibility-Principle). Eine Klasse "Rechnungsdrucker" sollte beispielsweise nur Rechnungen drucken und nicht gleichzeitig noch E-Mails versenden oder die Datenbank bereinigen. Der Vorteil liegt bei einem Fehler darin, dass man gezielt suchen kann.
(1.3) Separation of Concerns
Separation of Concerns (SoC) heißt grundsätzlich, dass verschiedene Aufgaben nicht vermischt werden sollen. Software wird komplex, wenn man Fachlichkeit (was die Software tut) und Technik (wie sie es speichert/überträgt) vermischt. Aspekte wie Sicherheit sind oft „Querschnittsaufgaben“ (Cross-cutting concerns), die man isoliert betrachten und lösen sollte, anstatt sie überall in den Code zu streuen.
Die „Quasar-Blutgruppen“
Um das Prinzip des SoC in der Praxis zu veranschaulichen, entwickelte Siedersleben im Projekt Quasar ein Klassifizierungssystem (Die Quasar Blutgruppen). Jede Komponente oder Klasse im System bekommt eine „Blutgruppe“, die ihre Rolle definiert. Ziel ist es, technische und fachliche Teile sauber zu trennen.
- 0 (Basis / Unabhängig): Grundlegende Bausteine ohne Fachlichkeit oder spezielle Technik (z. B. Standard-Bibliotheken, Strings, Integers). Wiederverwendbarkeit: Sehr hoch (überall nutzbar)
- T (Technik): Technische Schnittstellen oder Middleware (z. B. Datenbank-Treiber, APIs). Sie sind unabhängig vom Fachinhalt, hängen aber an einer Plattform. Wiederverwendbarkeit: Hoch (auf gleicher Plattform)
- A (Anwendung (App)): Die reine Fachlogik (z. B. Klasse „Kunde“, „Konto“). Enthält keine technische Infrastruktur. Wiederverwendbarkeit: Gering (nur in dieser Domäne)
- R: Repräsentation „Übersetzer“. Wandelt Fachobjekte in Formate für die Außenwelt um (z. B. XML, JSON, Verschlüsselung). Wiederverwendbarkeit: Nicht vorhanden (aber generierbar)
- AT (Anwendung + Technik): Hier ist Fachlogik fest mit Technik verdrahtet. Das führt zu „Legacy-Code“ (Altlasten), der schwer zu warten ist. Wiederverwendbarkeit: Sehr schlecht (zu vermeiden)
Software-Metriken sind Messinstrumente, um die Qualität von Software in Zahlen auszudrücken (quantitativ zu machen).
Software hat Eigenschaften, die schwer greifbar sind (z. B. „Wartbarkeit“, „Transparenz“ oder „Effizienz“). Metriken machen diese „unsichtbaren“ Aspekte sichtbar und objektiv vergleichbar. Das Management und die Entwickler sollen nicht nach Bauchgefühl entscheiden, sondern auf Basis von Daten steuern können.
Nicht jede Zahl ist sinnvoll. Damit eine Messung verlässlich ist, muss sie laut Hoffmann (2013) folgende Kriterien erfüllen:
- Objektivität: Das Ergebnis darf nicht von der Person abhängen, die misst. (Computergestützte Messungen sind hier am besten).
- Robustheit: Wenn man zweimal das Gleiche misst, muss zweimal die gleiche Zahl herauskommen (Wiederholbarkeit).
- Vergleichbarkeit: Man muss die Werte verschiedener Projekte miteinander vergleichen können.
- Ökonomie: Der Aufwand, die Daten zu erheben, darf nicht teurer sein als der Nutzen, den man daraus zieht.
- Korrelation: Die gemessene Zahl muss auch wirklich einen Rückschluss auf das zulassen, was man eigentlich wissen will (z. B. Hohe Zahl = Schlechte Wartbarkeit).
- Verwertbarkeit: Die Zahl darf nicht nur "da" sein, sie muss helfen, Entscheidungen für die Zukunft zu treffen.
Metriken der imperativen Programmierung
LOC & NCSS
Diese Metriken sind am einfachsten zu verstehen, aber auch am ungenausten, da sie stark vom Schreibstil des Programmierers abhängen.
-
LOC (Lines of Code): Man zählt einfach jede Zeile in der Datei. Leerzeilen und Kommentare blähen allerdings den Wert auf, ohne dass das Programm komplexer ist.
-
NCSS (Non Commented Source Statements): Man zählt nur die echten Befehlszeilen. Kommentare, Leerzeilen und Header werden ignoriert. Wenn man NCSS durch LOC teilt, sieht man, wie gut der Code dokumentiert ist (der „Dokumentationsgrad“).
Die Halstead-Metriken (Lexikalische Analyse)
Hier wird der Text der Software wie eine Sprache analysiert. Halstead schaut nicht auf die Zeilen, sondern auf die „Wörter“ (Tokens). Man zählt Operatoren (Verben/Aktionen wie +, -, =, if) und Operanden (Substantive/Daten wie x, 5, result). Aus der Anzahl dieser Elemente berechnet Halstead über Formeln verschiedene Werte:
- Länge N des Programmes:
N = N1 + N2. - Vokabular des Programms:
n = n1 + n2. - Halstead-Volumen (V):
V = N ∙ log 2nWie viele Entscheidungen mussten beim Schreiben getroffen werden? - Difficulty (D):
D = (n1 ∙ N2 ) / (2 ∙ n2). Wie schwer ist der Code zu verstehen? - Effort (E):
E = D ∙ VWie hoch war der Aufwand, das Programm zu verstehen?
Diese Metrik ist gut, um die Wartbarkeit einzuschätzen, aber manchmal ungenau, da die logische Struktur ignoriert wird.
Die McCabe-Metrik (Zyklomatische Komplexität)
Dies ist eine der wichtigsten Metriken für die Testplanung. Sie misst die logische Komplexität des Programmflusses (Kontrollfluss). Man stellt das Programm als Graphen dar (Knoten sind Befehle, Kanten sind die Verbindungen).
Die Formel: M=E−N+2 mit
E= Anzahl der Kanten/Verbindungen undN= Anzahl der Knoten/Befehle
Die Zahl M sagt aus, wie viele verschiedene Wege es durch ein Programm gibt (durch if, while, etc.) wobei
- Je höher die Zahl, desto schlechter die Wartbarkeit.
- Je höher die Zahl, desto mehr Testfälle sind notwendig (um jeden Pfad einmal abzulaufen).
Als Faustregel gilt, dass ein Wert über 10 als kritisch gilt und vermieden werden sollte (z.B. durch Refactoring).
Metriken der objektorientierten Programmierung
Metriken (wie LOC oder McCabe) eignen sich nicht für modernes (OOP) Software-Engineering: Sie verstehen keine Klassen, keine Vererbung und keine Objekte.
Deshalb wurden objektorientierte Metriken entwickelt. Diese schauen nicht nur auf den Code in einer Funktion, sondern darauf, wie Klassen miteinander verwandt sind und interagieren.
Man kann die Metriken in drei Kategorien aufteilen:
- Vererbungsmetriken (Die Hierarchie) Diese Metriken messen den "Stammbaum" deiner Klassen.
-
DIT (Depth of Inheritance Tree): Wie tief steckt eine Klasse in der Vererbungshierarchie? Es wird der Abstand von der Klasse bis ganz oben zur Wurzel-Klasse gemessen. Je tiefer, desto komplexer und schwerer zu verstehen. Der Wert sollte nicht größer als 6 oder 7 sein.
-
NOC (Number of Children): Wie viele direkte Unterklassen hat eine Klasse? Eine Klasse mit vielen "Kindern" (hoher NOC) ist sehr einflussreich. Wenn hier ein Fehler entsteht, erben ihn alle Kinder. Sie muss extrem gut getestet werden.
- Kohäsionsmetrik (Der innere Zusammenhalt)
Hier geht es darum, ob eine Klasse logisch zusammengehört oder ob sie Dinge tut, die nichts miteinander zu tun haben.
- LCOM (Lack of Cohesion in Methods): Wörtlich: „Mangel an Zusammenhalt“. Man prüft, ob die Methoden einer Klasse auf die gleichen Attribute zugreifen.Es soll idealtypisch ein niedriger LCOM-Wert erreicht werden. Ein hoher Lack of Cohesion ist schlecht. Ein niedriger Wert (gegen 0) bedeutet, dass alle Methoden gut zusammenarbeiten (hohe Kohäsion).
- Struktur- und Kopplungsmetriken (Die Vernetzung). Diese Metriken messen, wie stark Klassen voneinander abhängig sind (Kopplung).
- Fan-In (Fin): Wie viele andere Klassen nutzen mich? Ein niedriger Fan-In deutet oft auf Klassen am "oberen Ende" der Architektur hin (Steuerungseinheiten, die niemanden bedienen müssen, sondern selbst agieren).
- Fan-Out (Fout): Wie viele andere Klassen nutze ich? Ein hoher Fan-Out bedeutet, dass eine Klasse viele andere steuert oder delegiert.
- CBO (Coupling Between Objects): Ein allgemeines Maß dafür, mit wie vielen anderen Klassen eine Klasse verbunden ist. Das Ziel ist es, die Abhängigkeiten zu minimieren (leichtere Wartung).
(1.4) Divide et Impera - Divide and Conquer
„Divide et Impera“ (Teile und Herrsche) ist eine Methode, um große, komplexe Softwareprojekte erst beherrschbar zu machen.
Die Grundidee hinter diesem Prinzip liegt es darin, die Komplexität durch Zerlegung zu reduzieren. Ein komplettes Softwaresystem ist zu groß, um es als Ganzes zu verstehen oder zu bauen. Deshalb zerlegt man das „große Problem“ in viele kleine, voneinander unabhängige „Teilprobleme“. Wenn man die Teillösungen zusammensetzt, hat man das Gesamtsystem. Das funktioniert nur, wenn die Schnittstellen (wie wir sie vorher besprochen haben) sauber definiert sind.
Dekomposition
Wie wird ein System zerlegt? Es gibt unterschiedliche Ansätze:
- Funktionale Dekomposition (Nach Aufgaben): Man zerlegt das System anhand dessen, was es tut. Beispiel: „Kundenverwaltung“ wird zerlegt in „Anlegen“, „Bearbeiten“, „Löschen“.
- Strukturelle Dekomposition (Nach Bausteinen): Man zerlegt das System in technische Ebenen oder Komponenten. Beispiel: „Webshop“ wird zerlegt in „Benutzeroberfläche“ (UI), „Logik-Server“, „Datenbank“.
Parametrisierung
Zusätzlich zur Zerlegung sollen Module konfigurierbar (parametrisierbar) sein. Anstatt ein Modul starr für einen Zweck zu bauen, baut man es so, dass es durch Einstellungen (Parameter) an verschiedene Situationen angepasst werden kann. Das erhöht die Wiederverwendung. Dadurch soll eine bessere Austauschbarkeit und höhere Flexibilität der Modulen erreicht werden. Teams können gleichzeitig an verschiedenen Modulen arbeiten (Arbeitsteilung = Parallelität). Wenn sich eine Anforderung ändert (z. B. „Neue Steuerberechnung“), muss man nur ein Modul anfassen, nicht das ganze System (Warbarkeit). Wenn die Schnittstelle stimmt, kann man ein altes Modul einfach gegen ein besseres austauschen (wie einen alten Motor in einem Auto), ohne dass der Rest des Autos merkt, dass etwas passiert ist (Austauschbarkeit).
(1.5) Design by Contract
Das Prinzip Design by Contract (vertragsbasierte Programmierung) lässt sich durch möglichst frühzeitige Spezifikation von Schnittstellen umsetzen, die über den Systemlebenszyklus hinweg möglichst stabil gehalten werden. Dies erleichtert zudem die Abstraktion der konkreten Implementierung. Es erweist sich als hilfreich, Schnittstellen so zu gestalten, dass in sich geschlossene Teilaufgaben gelöst werden, und diese vollständig und detailliert zu beschreiben.
Die Herausforderung besteht darin, dennoch allgemein zu bleiben. Dazu muss ggf. eine speziellere Aufgabenstellung, die etwa im Rahmen der Dekomposition der Aufgabenstellung anfällt, so verallgemeinert werden, dass die speziellere Aufgabe durch entsprechende Parameterauswahl gelöst wird. Ziel dieses Vorgehens ist der Erhalt sogenannter „schmaler“ Schnittstellen, also von Schnittstellen mit einer überschaubaren Parameteranzahl. Zudem kann die entstehende Komponente desto besser für andere Aufgabenstellungen genutzt werden, je allgemeiner sie ausgelegt ist. Fazit: „Die Schnittstellenbeschreibung bildet einen Vertrag zwischen den Nutzern und den Implementierern einer Schnittstelle. Der Nutzer verlässt sich auf das in der Schnittstelle spezifizierte Verhalten, der Implementierer garantiert die Schnittstelle“ (Broy/Kuhrmann 2021, S.341).
(2.) Architekturenentwurf
Der Architekturentwurf sieht sich aufgrund der zunehmenden Vernetzung eingebetteter Software mit massiv steigenden Anforderungen konfrontiert. Für den Architekten bedeutet dies primär die Bewältigung einer wachsenden Systemkomplexität sowie die Koordination der Interaktionen zwischen dem System, seiner Umgebung und anderen informationstechnischen Einheiten. Insbesondere der autonome Einsatz in unkontrollierten Umgebungen erfordert dabei ein Höchstmaß an Korrektheit, Robustheit und Sicherheit. Um diesen Herausforderungen zu begegnen, ist die explizite Modellierung von Systemen notwendig, wobei einzelne Module passgenaue Architektursichten bieten und trotz ihrer fachlichen Spezialisierung eine nahtlose technische Verknüpfung untereinander gewährleisten müssen.
(2.1.) Strukturierung komplexer Softwaresysteme
Die Strukturierung komplexer Softwaresysteme erfolgt durch die architektonische Zerlegung des Systems in einzelne Komponenten wie Module oder Klassen, wobei deren Qualität sowie die Beschaffenheit ihrer Schnittstellen die Güte des Gesamtsystems bestimmen.
Die Art der Interaktion zwischen diesen Teilsystemen wird durch das Programmierparadigma geprägt, was in der Objektorientierung konkret durch Methodenaufrufe an definierten Schnittstellen umgesetzt wird.
Aufgabe des Architekturentwurfs ist es, diese Gliederung hierarchisch vorzunehmen und die Vernetzung sowie das Zusammenspiel der Komponenten festzulegen. Da durch die Prinzipien der Kapselung und des Information Hiding das Innere der Komponenten verborgen bleibt, genügt für das Verständnis der Funktionalität die reine Betrachtung der Schnittstellenspezifikation.
In der Praxis etabliert man für wiederkehrende Aufgaben - wie die Verbindung von Persistenzschichten oder grafischen Oberflächen - feste Grundmuster, die zur Vermeidung von Redundanzen nur einmal präzise beschrieben werden, wobei man hierbei noch zwischen zur Laufzeit unveränderlichen statischen und veränderbaren dynamischen Strukturen differenziert.
(2.1.1.) Statische Softwarestrukturen
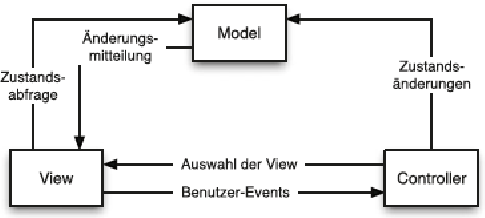
Als prominentes Beispiel für statische Softwarestrukturen, insbesondere zur Anbindung grafischer Benutzeroberflächen an die fachlichen Bestandteile eines Systems, dient das Model-View-Controller-Muster (MVC). Dieses Muster erzwingt eine strikte Aufgabenteilung innerhalb der Architektur, indem es die Darstellung, die Steuerung und die Datenhaltung voneinander entkoppelt.
Während die Modellbestandteile die eigentliche Fachlogik kapseln und für die Verwaltung des Systemzustands sowie die Datenspeicherung verantwortlich sind, sorgen die View-Elemente für die Visualisierung dieser Daten und gewährleisten die Konsistenz zwischen dem internen Modell und der Anzeige an der Oberfläche. Die Interaktion des Nutzers wird schließlich durch die Controller-Komponenten gesteuert, welche die eingehenden Benutzeraktionen in konkrete Funktionsaufrufe an das zugrundeliegende Modell übersetzen.
(2.1.2.) Dynamische Softwarestrukturen
Die Abbildung dynamischer Softwarestrukturen stützt sich zwar auf etablierte Modelle wie UML und SysML, steht jedoch insbesondere bei eingebetteten Systemen vor der Herausforderung, das komplexe Zusammenspiel von Hardware, Betriebssystem, Speicher und Anwendung adäquat zu dokumentieren. Es ist daher eine zu UML kompatible Beschreibungsform erforderlich, welche die spezifische Dynamik an der Schnittstelle zwischen Hard- und Software berücksichtigt. Ergänzend hierzu wird ein komponentenbasierter Ansatz verfolgt, der aufgrund der festen Einbettung der Software in einen größeren Gesamtkontext und der fehlenden Möglichkeit zur ständigen Neukonfiguration notwendig ist. Dies impliziert, dass die Architektur von Beginn an ein stabiles, auf alle Komponenten übertragbares Ausnahme- und Fehlerkonzept beinhalten muss, um die Robustheit des Gesamtsystems dauerhaft zu sichern.
(2.2.) Architektursichten
Die Dokumentation einer Softwarearchitektur unterstützt deren Diskussion und Optimierung sowie die Wissenssicherung. Hierbei spielen neben der Wahl geeigneter Werkzeuge auch Art und Umfang eine erhebliche Rolle. Eine der Standardmethoden zur (System-)Entwurfsvisualisierung ist die Unified Modeling Language (UML), eine universelle Entwicklungs- und Modellierungssprache, die geschaffen wurde, um verschiedene Softwaredesignansätze und Notationen zu vereinheitlichen.
(2.2.1.) Warum Dokumentation?
Die Dokumentation von Softwarearchitekturen dient primär der Sicherstellung einer reibungslosen Kommunikation zwischen dem Architekten und allen weiteren Projektbeteiligten, wobei dem Architekten die Verantwortung für eine verständliche und integrative Aufbereitung obliegt. Da die Komplexität eines modernen Softwaresystems jedoch nicht durch eine einzelne Abbildung erfassbar ist, etablierte Philippe Kruchten 1995 das sogenannte „4+1-Sichtenmodell“. Dieses Modell reduziert die Darstellungskomplexität durch die gesonderte Betrachtung verschiedener Teilaspekte des Systems und prägte damit maßgeblich den heute zentralen Begriff der Architektursichten.
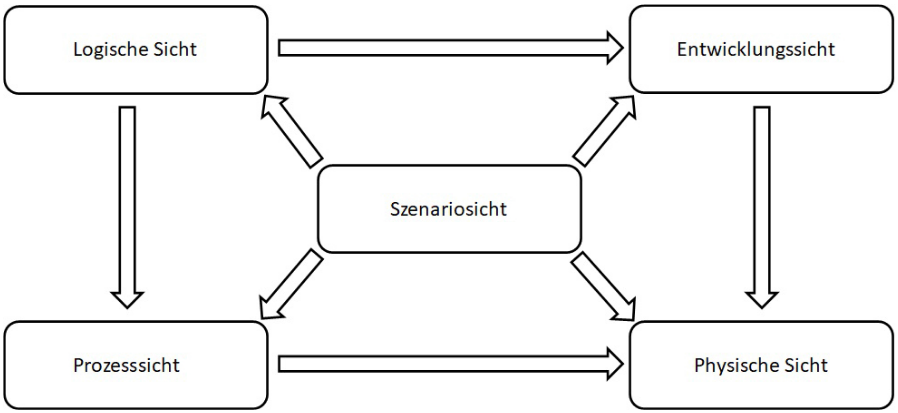
Der Begriff Architektursichten bezeichnet das Betrachten komplexer Systeme aus verschiedenen Perspektiven, um die Interessen bzw. Anforderungen aller am Prozess Beteiligten berücksichtigen zu können. Es wird also ein- und dieselbe Komponente bzw. ein- und derselbe Prozess aus der Sicht aller involvierten Akteure beleuchtet, um das System verständlich beschreiben zu können und die Fehlerquote gering zu halten. Anhand der Architektursichten wird demnach die Wahrnehmung aller involvierten Per- sonengruppen visualisiert, nämlich Entwickler, Administratoren, Manager und Endanwender. Auf diese Weise können verschiedene Szenarien (Use Cases) beschrieben werden, welche die Funktionalität des Systems wiedergeben.
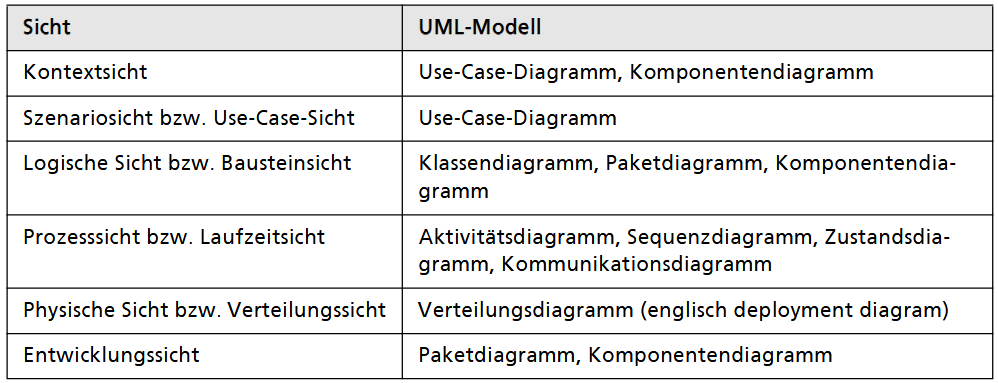
Gängige deutsche Bezeichnungen in der Literatur sind Kontextabgrenzung bzw. Systemkontext, Bausteinsicht, Laufzeitsicht, Verteilungssicht und Use-Case-Sicht (Szenarios).
(2.2.2.) Dokumentationsstandards
Die zunehmende Komplexität von Softwareprojekten macht einheitliche Dokumentations- und Kommunikationsstandards unverzichtbar, um eine verständliche Fachsprache zwischen allen Beteiligten zu gewährleisten.
Die Gliederungsvorlage: arc42
Für die Strukturierung der Architekturdokumentation hat sich das Open-Source-Template arc42 als Standard etabliert. Es unterteilt die Dokumentation in 12 Kapitel, die weit über reine Diagramme hinausgehen. Neben den reinen Architektursichten (Baustein-, Laufzeit-, Verteilungssicht) erfasst arc42 explizit auch:
- Kontext und Ziele: Aufgabenstellung, Stakeholder und Randbedingungen.
- Begründungen: Warum wurden bestimmte Entwurfsentscheidungen getroffen?
- Qualität & Risiken: Technische Schulden, Qualitätsbäume und Risikomanagement.
UML Die Unified Modeling Language (UML)
UML ist seit 1997 der weltweite Standard der OMG (Object Management Group) für die grafische Modellierung. Trotz Kritik an ihrer Komplexität ist sie konkurrenzlos. Sie bietet für jede Architektursicht spezifische Diagrammarten an. Architekturdiagramme dienen als „Blaupausen“ (ähnlich Bauplänen in der Architektur). Sie schaffen eine gemeinsame Symbolsprache, fördern die Teamarbeit und helfen, die Vision des Systems auf einer hohen Abstraktionsebene mit den Kundenanforderungen abzugleichen.
UML Erweiterungen für spezielle Anforderungen
Da UML primär für reine Software gedacht war, entstanden Erweiterungen für komplexere Systeme:
- SysML (Systems Modeling Language): Eine Teilmenge von UML 2, erweitert für das Systems Engineering. Sie betrachtet nicht nur Software, sondern das Gesamtsystem (Hardware, Personal, Prozesse, Räume) und dient der interdisziplinären Modellierung.
- MARTE: Ein UML-Profil speziell für eingebettete Systeme (Embedded Systems) mit harten Echtzeitanforderungen.
Analysemethoden
- Strukturierte Analyse (SA): Ein methodisches Vorgehen, bei dem das System ausgehend von einem Kontextdiagramm hierarchisch top-down immer feiner in Datenflussdiagramme zerlegt wird.
- Intuitive Analyse: Der traditionelle Gegenentwurf zur strukturierten Analyse. Sie basiert auf Expertenwissen, Erfahrung und Analogien („Bauchgefühl“), bleibt aber bis zum ersten Entwurf oft ein intransparenter, individueller Denkprozess.
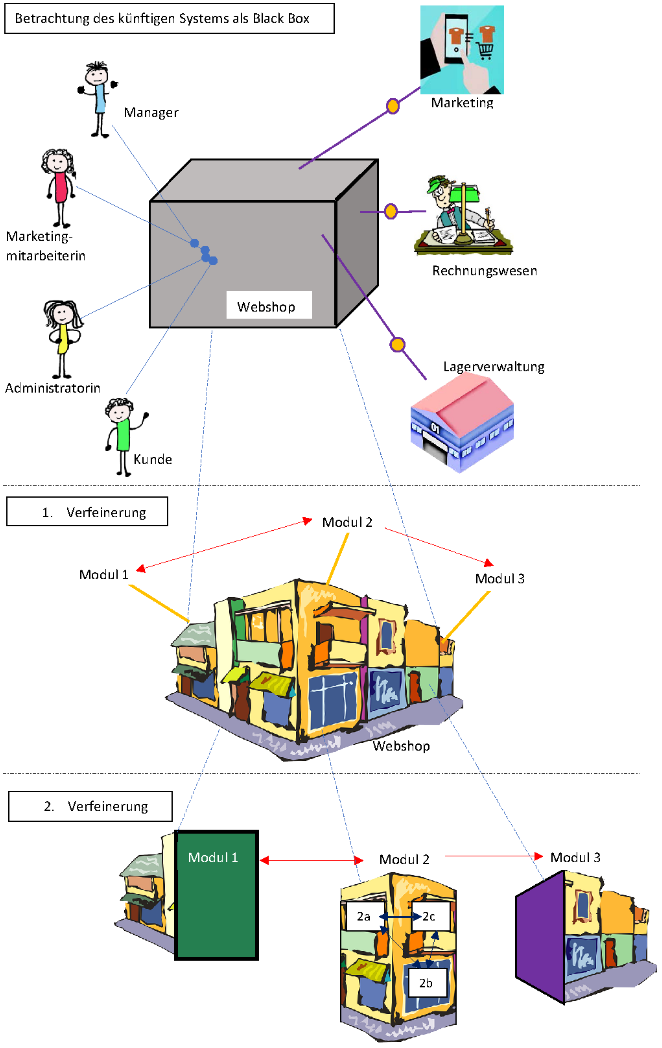
(2.2.3.) Systemkontext (context view)
Der Systemkontext stellt die übergeordnete Sicht auf die Softwarearchitektur dar und betrachtet das System aus der Vogelperspektive als reine Blackbox. Ziel dieser Sicht ist es, die exakte Grenze zwischen dem eigentlichen System und seiner Umgebung (dem Kontext) zu ziehen. Dabei werden externe Einflussfaktoren, Benutzergruppen sowie die Schnittstellen für den Daten- und Informationsfluss (Input/Output) identifiziert. Zur grafischen Darstellung eignen sich Kontextdiagramme (aus der strukturierten Analyse) oder UML-Diagramme wie das Komponenten-, Kommunikations- oder Klassendiagramm.
Die Definition der Systemgrenze erfolgt anhand konkreter Kriterien wie den Hauptaufgaben, der Nutzeridentifikation, der Betriebsart (z. B. Batch vs. GUI) und der Art der Datenverarbeitung. Diese Analyse liefert nicht nur die typischen Anwendungsfälle und Schnittstellenanforderungen, sondern dient als fundamentale Basis für den ersten Architekturentwurf, da sich aus dem Kontext bereits erste Schlüsselabstraktionen (wie Fachklassen oder funktionale Blöcke) ableiten lassen.
(2.2.4.) Bausteinsicht / logische Sicht (logical view)
Die Bausteinsicht beschreibt den statischen Aufbau eines Softwaresystems, indem sie Subsysteme, Komponenten und Module sowie deren Schnittstellen definiert, ohne dabei interne Prozesse zu berücksichtigen. Die Modellierung erfolgt üblicherweise über einen Top-Down-Ansatz, bei dem die Blackbox des Systemkontexts in mehreren Verfeinerungsstufen in detaillierte Bausteine gegliedert wird, wobei UML-Diagramme wie Komponenten-, Klassen- und Paketdiagramme zur Visualisierung dienen.
Ein zentrales Entwurfsprinzip ist hierbei die konsequente Trennung von fachlichen und technischen Strukturen, wobei bewährte Architekturmuster (wie Schichtenarchitekturen oder Domain-Modelle) als Orientierung dienen sollten. Zur Qualitätssicherung der Bausteinstruktur empfiehlt sich ein iterativer Prozess, der Expertenaustausch, Prototyping und einen testgetriebenen Ansatz (TDD) kombiniert. Sollte der Entwurf der statischen Struktur stagnieren, sieht die Methodik den Wechsel in die Laufzeitsicht vor, um durch die Analyse dynamischer Szenarien neue Erkenntnisse für die Bausteinstruktur zu gewinnen.
(2.2.5.) Laufzeitsicht (process view)
Die Laufzeitsicht dient der Dokumentation dynamischer Systemaspekte und fokussiert sich auf das Verhalten sowie das Zusammenspiel von Instanzen während der Programmausführung. Im Gegensatz zur statischen Bausteinsicht werden hier ausschließlich Bausteine betrachtet, die zur Laufzeit tatsächlich als ausführbare Einheiten (Exemplare) existieren. Die Beziehungen zwischen diesen Einheiten werden primär über Kontroll- und Datenflüsse definiert.
Sequenzdiagramm
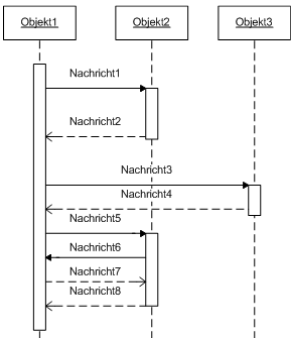
Aktivitätsdiagramm
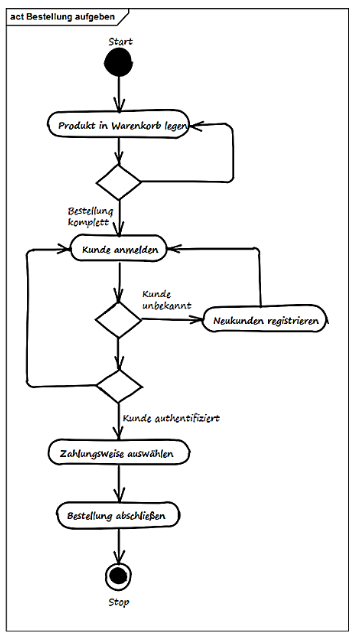
(2.2.6.) Verteilungssicht (physical view)
Die Verteilungssicht (oder Infrastruktursicht) beschreibt die physische Ablaufumgebung eines Softwaresystems. Sie fungiert als technische Landkarte, die alle Hardwarekomponenten wie Server, Prozessoren, Speicher und Netzwerkgeräte sowie die darauf installierten Laufzeitumgebungen und Betriebssysteme dokumentiert. Ein wesentlicher Bestandteil dieser Sicht ist die Definition der Kommunikationswege und Protokolle zwischen den physischen Einheiten.
Zusätzlich zur rein räumlichen Zuordnung werden in der Verteilungssicht technische Parameter wie Kapazitäten, Leistungsdaten und Mengengerüste erfasst, um die Anforderungen an die Infrastruktur abzubilden. Zur grafischen Darstellung wird in der UML vorzugsweise das Verteilungsdiagramm genutzt, wobei auch Komponenten- und Paketsymbole verwendet werden, um die Platzierung der Softwarebausteine auf der jeweiligen Hardware zu visualisieren.
Alle Architektursichten decken ‒ bei aller Bedeutung, die sie in der Dokumentation von Softwarearchitektur haben ‒ jede nur einen Teil des Gesamtumfangs ab. Nur als „Gesamtpaket“ erlauben sie eine vollständige Sicht auf die Architektur. Grundsätzlich gilt für die Dokumentation von Softwarearchitekturen: Informationen sollten nach ihrem am Projekt ausgerichteten Sinn (in diesem Fall dem Architektur verstehen) selektiert und somit entweder hinzugefügt oder weggelassen werden. Das bedeutet, dass möglicherweise weitere Sichten Berücksichtigung finden müssen, etwa wenn Informationen zu Datenstrukturen oder Datenhaltung benötigt werden.
(2.3.) Klar strukturieren mit Domänen - domaingetriebenes Design
Domain-driven Design (DDD) verfolgt das Ziel, die Komplexität großer Softwareprojekte durch eine strikte Abbildung der Fachlichkeit in sauber abgegrenzten Domänen zu beherrschen. Dabei kapseln Klassen die spezifischen funktionalen Aspekte eines Anwendungsgebiets, wobei Techniken der objektorientierten Entwicklung genutzt werden, um ein transparentes Domänenmodell zu schaffen. Ein zentrales Element des DDD ist die Etablierung einer einheitlichen Terminologie („Ubiquitous Language“), die eine reibungsfreie Kommunikation zwischen Fachexperten und Softwarearchitekten ermöglicht. Aufgrund des hohen Modellierungsaufwands und der notwendigen Standardisierung ist dieser Ansatz primär für geschäftskritische und hochkomplexe Projekte geeignet, bei denen die fachliche Korrektheit und Verständlichkeit im Vordergrund stehen.
(2.3.1.) Ubiquitous Language
Die Ubiquitous Language ist das Herzstück der Kommunikation im Domain-driven Design. Sie dient dazu, Missverständnisse zwischen Fachabteilung und IT zu eliminieren, indem eine identische Terminologie für alle Beteiligten sowie im Quellcode verbindlich festgelegt wird. Diese Sprache wird innerhalb eines spezifischen Kontextes (Bounded Context) konsequent angewendet, sodass das Domänenmodell im Code direkt die Sprache der Experten widerspiegelt. Dies erhöht die Transparenz und stellt sicher, dass die Softwarelösung exakt die fachlichen Anforderungen erfüllt.
(2.3.2.) Elemente des Domain-driven Designs
Eine Domäne kann nach dem DDD-Ansatz aus den folgenden Bestandteilen erstellt werden (vgl. Kraus 2018, o. S.):
- Aggregate: Einheit aus Objekten und deren Beziehungen.
- Assoziationen: Beziehungen zwischen Objekten des Modells.
- Entitäten: Objekte mit dynamischen oder nicht eindeutigen Eigenschaften, die über ihre Einzigartigkeit definiert sind (z. B. Personen).
- Fachliche Ereignisse: Spezielle Objekte registrieren fachlich relevante Ereignisse und machen sie für andere Domänenteile sichtbar (z. B. Ereignisse in einem Aggregat anderen Aggregaten der Domäne mitteilen).
- Fabriken: Für komplexe Szenarien können verschiedene Erzeugungsmuster (meist factory oder builder patterns) herangezogen werden.
- Module: fachliche Bestandteile der Domäne.
- Repositories: saubere Trennung von Domänen- und Datenschicht für die Abstrahierung des Systems.
- Serviceobjekte: fachlich relevante Funktionalitäten, die für mehrere Objekte der Domäne wichtig sind.
- Wertobjekte: Objekte, die durch ihre Eigenschaften eindeutig definiert sind und typischerweise unveränderlich bleiben.
(2.3.3.) Der Leitfaden
Um die korrekte Funktionsweise komplexer Systeme abzusichern, gibt der DDD-Ansatz klar definierte Vorgehensweisen vor, die als Handlungsleitfaden für die interdisziplinäre Zusammenarbeit dienen. Da sich das Domänenmodell im Projektverlauf durch neue Erkenntnisse oder veränderte Anforderungen stetig weiterentwickelt, ist ein hohes Maß an Integrationsdisziplin erforderlich. Hierbei kommt der Continuous Integration (CI) eine Schlüsselrolle zu: Sie ermöglicht es, Module kontinuierlich in die Gesamtcodebasis einzuspeisen und zu prüfen. Dies verhindert die früher üblichen Integrationsfehler bei Projektabschluss und stellt sicher, dass das System trotz fortlaufender Modelländerungen stabil und konsistent bleibt.
(2.3.4.) Kernfachlichkeit
Das Domain-driven Design fokussiert sich primär auf die Kernfachlichkeit, welche die wettbewerbsentscheidenden Funktionen eines Systems kapselt. Um die Verständlichkeit und Wartbarkeit bei hoher Komplexität zu gewährleisten, kann diese Kernfachlichkeit als separates Modul oder – bei übergreifender Nutzung durch verschiedene Systemteile - als geteilter Kern (Shared Kernel) modelliert werden. Alle unterstützenden Funktionen, die nicht zum Kern des Geschäftsmodells gehören, werden als generische Subfachlichkeiten ausgelagert oder durch Standardsoftware abgedeckt.
Die organisatorische Steuerung erfolgt über explizite Kontextgrenzen, die in einer Kontextübersicht samt aller Schnittstellen präzise definiert sind. Die Zusammenarbeit zwischen den beteiligten Projektteams wird dabei häufig über eine Kunde-Lieferant-Beziehung strukturiert, wodurch fachliche Anforderungen und technische Umsetzung klar voneinander abgegrenzt und Verantwortlichkeiten eindeutig zugewiesen werden.
(2.3.5.) Architekturbewertung
Die Architekturbewertung dient der frühzeitigen Identifikation von Fehlern und Komplexitätsrisiken, um den wirtschaftlichen Erfolg eines Projekts zu sichern. Im Fokus stehen dabei vor allem nicht-funktionale Anforderungen (wie Performance, Sicherheit und Wartbarkeit), die mithilfe von Qualitätsszenarien konkretisiert und messbar gemacht werden. Ein zentrales Instrument ist hierbei der Utility Tree, der die Qualitätsziele hierarchisch ordnet und priorisiert.
Das etablierte Verfahren ATAM (Architecture Tradeoff Analysis method) untersucht in vier Phasen, wie gut eine Architektur diese Szenarien erfüllt. Dabei werden gezielt Sensitivity Points (kritische Komponenten für ein Qualitätsziel) und Trade-off Points (Komponenten, die mehrere, teils widersprüchliche Ziele beeinflussen) identifiziert. Das Ergebnis der Bewertung ist kein „Bestanden“, sondern eine fundierte Entscheidungsgrundlage, die Risiken aufzeigt und notwendige Kompromisse zwischen verschiedenen Qualitätsattributen transparent macht. Jedes Szenario wird dabei präzise durch einen Stimulus (Ereignis), einen Kontext (Umgebung) und eine messbare Reaktion des Systems definiert.
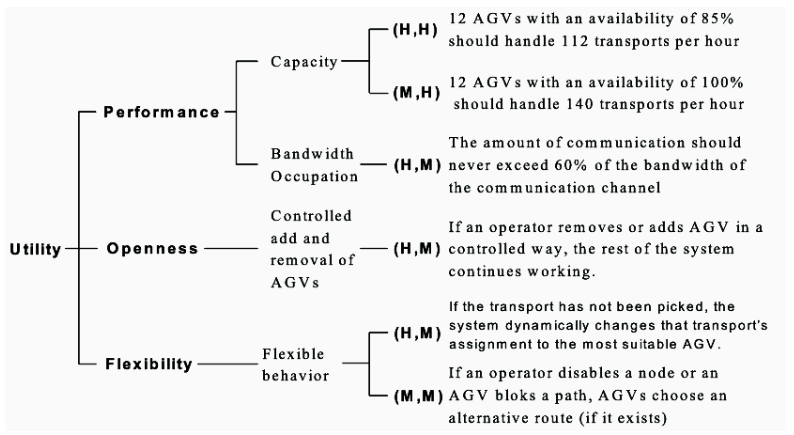
(3) Architekturmuster
Architekturmuster definieren die fundamentale Grundstruktur eines Softwaresystems und legen fest, wie dessen Hauptkomponenten auf oberster Ebene organisiert und vernetzt sind. Im Gegensatz dazu adressieren Entwurfsmuster (Design Patterns) spezifische, implementierungsnahe Probleme auf Ebene der Klassen und Objekte. Beiden gemeinsam ist der Charakter als bewährte Lösungsschablone für wiederkehrende Entwurfsprobleme.
Der Einsatz dieser Muster zielt darauf ab, eine optimale Balance zwischen positiven Qualitätsmerkmalen wie Wartbarkeit, Testbarkeit und Wiederverwendbarkeit einerseits sowie systembedingten Nachteilen wie erhöhtem Speicherbedarf oder Kommunikations-Overhead andererseits zu finden. Während die Grenze zwischen beiden Musterarten in der Praxis oft unscharf ist, bildet das Architekturmuster stets den übergeordneten Rahmen, in dem die detaillierteren Entwurfsmuster angewendet werden.
(3.1.) Design Pattern - Entwurfmuster
Entwurfsmuster (Design Patterns) stellen bewährte und standardisierte Lösungsansätze für wiederkehrende Aufgaben im Softwareentwurf dar. Ihr Einsatz dient der Sicherung von Entwicklungs-Know-how, der Steigerung der Produktivität sowie der Verbesserung der Softwarequalität und Wartbarkeit. Jedes Muster folgt einem einheitlichen Beschreibungsschema, das den Anwendungskontext, die spezifische Aufgabenstellung, das strukturelle Lösungsprinzip (oft mittels UML visualisiert) sowie eine abschließende Bewertung der Vor- und Nachteile umfasst.
Systematisch werden Entwurfsmuster nach ihrem Zweck in Erzeugungs-, Struktur- und Verhaltensmuster klassifiziert. Während einfache Probleme oft durch ein einzelnes Muster gelöst werden können, erfordern komplexe Anforderungen häufig die Kombination mehrerer Muster. Für eine erfolgreiche Integration in den Entwicklungsprozess ist neben der technischen Auswahl auch die organisatorische Verankerung entscheidend, etwa durch Richtlinien, Musterdatenhaltung und gezielte Weiterbildung der Entwickler. Als prominente Beispiele dienen das Strukturmuster Fassade und das Verhaltensmuster Beobachter.
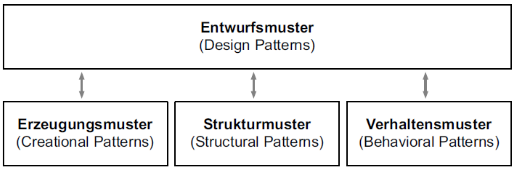
Für mehr über dieses Thema s. Design Patterns
(3.1.1.) Fassade Muster (Facade pattern)
Das Strukturmuster Fassade dient der Vereinfachung des Zugriffs auf komplexe Teilsysteme. Es führt eine neue Schnittstellenklasse (die Fassade) ein, die als einzige Anlaufstelle für Client-Klassen fungiert und einen reduzierten, genau auf die benötigten Anforderungen zugeschnittenen Funktionsumfang bereitstellt.
Dadurch wird die Komplexität des dahinterliegenden Systems - etwa bei unübersichtlichen Legacy-Systemen - vor dem Client verborgen (Kapselung). Der Client benötigt keine Kenntnisse über die interne Struktur oder die einzelnen Klassen des Subsystems, was die Kopplung zwischen den Systemteilen verringert und die Wartbarkeit erhöht. Je nach Anwendungszweck können für dasselbe Teilsystem auch mehrere unterschiedliche Fassaden existieren, um verschiedene Funktionsausschnitte bereitzustellen.
(3.1.2.) Beobachter Muster (Observer pattern)
Das Verhaltensmuster Beobachter setzt man ein, wenn mehrere abhängige Observer Objekte über Statusänderungen eines zu beobachtenden Objektes informiert werden sollen. Das zu beobachtende Objekt könnte beispielsweise eine Datentabelle sein, deren Inhalt sich ständig durch neue Messungen aktualisiert. Diese Daten sollen in mehreren Benutzeroberflächen (hier also die Observer-Objekte) stets aktuell angezeigt werden. Je nach Anzahl der Observer-Objekte können regelmäßige Statusabfragen zu einer großen, teilweise unnötigen Last führen. Darum wird die Beobachtung an ein Subject-Objekt delegiert. Die Oberserver registrieren sich beim Subject. Dieses führt eine aktuelle Liste der Observer und informiert diese über relevante Ereignisse, zum Beispiel neue Daten oder eine Statusänderung des beobachteten Objektes
(3.2.) Architekturmuster
Allgemein lassen sich Architekturmuster den Kategorien Basisstrukturierung, Verteilung und Steuerung zuordnen.
(3.3.) Basisstrukturierung
Die Basisstruktur von Softwarearchitekturen wird differenziert in das sog. Blackboard, die Schichtenarchitektur bzw. Pipes und Filter. Diese Muster gehören zur Bausteinsicht.
(3.3.1.) Blackboard
Beim Architekturmuster des sog. Schwarzen Bretts (Blackboard) kommunizieren die Komponenten indirekt über ein gemeinsam genutztes Schwarzes Brett, das als einheitliche Datenablage fungiert. Das System ist sehr einfach strukturiert. Es greift also eine Vielzahl an Komponenten, die untereinander nicht vernetzt sind, auf die gleichen Daten zu. Ein Merkmal dieser Struktur ist die Möglichkeit, den Datennutzern Änderungsmitteilungen zukommen zu lassen und Zugriffsberechtigungen und Werte zu validieren, um eine willkürliche Datenmanipulation zu verhindern.
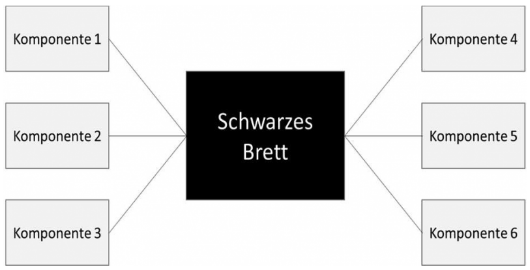
Ein Nachteil dieser Struktur ist der eher langsame Datenzugriff. Dieser dauert entsprechend der Komplexität des Gesamtsystems länger als bei anderen Strukturmustern, wobei das Blackboard einen Flaschenhals bildet.
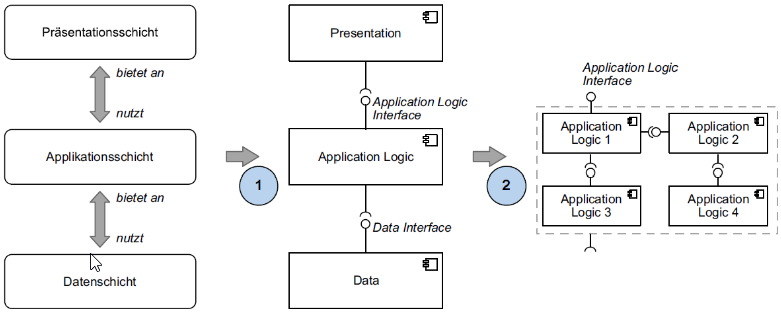
(3.3.2.) Schichtenbildung und Schichtenarchitekturen
Die Schichtenarchitektur (Layering) strukturiert ein System in funktionale Ebenen, wobei jede Schicht über definierte Schnittstellen Dienste für die darüberliegende Ebene bereitstellt und selbst auf die Dienste der darunterliegenden Ebene zugreift. Bei einer strikten Schichtung ist die Kommunikation streng auf die unmittelbar benachbarten Ebenen begrenzt.
Wichtige Aspekte der Umsetzung sind:
-
Verfeinerung: Schichten werden intern in Teilsysteme und Module gegliedert, wobei das Fassade-Muster (Application Logic Interface) eingesetzt wird, um interne Strukturen von den nach außen gerichteten Schnittstellen zu entkoppeln.
-
Frameworks: Das Enterprise Architecture Framework nutzt dieses Prinzip, um Unternehmensarchitekturen durch die Gliederung in Domänen, Schichten und Ansichten handhabbar zu machen.
-
Standard-Beispiel: Die häufigste Ausprägung der Schichtenarchitektur ist das MVC-Muster (Model-View-Controller), das insbesondere bei Webanwendungen dominiert.
-
Qualitätsziele: Auch hier stehen die Entwurfsprinzipien Kopplung und Kohäsion im Vordergrund, um ein wartbares und einfach zu verstehendes Gesamtsystem zu schaffen.
(3.2.3.) Pipes und Filter
Pipes und Filter - häufig als Datenflusssystem bezeichnet - bilden eine Struktur für datenstromverarbeitende Systeme.

Im Bild sind die Filter jeweils als Verarbeitungsschritte erkennbar - Filter haben jeweils eine Datenein- bzw. -ausgabe. Die eingehenden Daten werden in jedem Verarbeitungsschritt entsprechend dem jeweiligen Filter umgewandelt. Dabei können den Daten, je nach bestehenden Anforderungen, Informationen hinzugefügt oder (bis hin zur kompletten Ersetzung) entnommen werden, oder komplett ersetzt werden. Filter sind demnach aktive Bauteile. Pipes hingegen stellen lediglich die Verbindung zwischen den einzelnen Verarbeitungsschritten her. Die Daten, die einen Filter verlassen, werden unverändert zum nächsten Filter weitergeleitet. Eine Neuanordnung der Verarbeitungsschritte ist jederzeit möglich. Dadurch können immer neue Kombinationen geschaffen werden. (Vgl. Wong 2020.) Die Vorteile dieser Architektur liegen in der Möglichkeit der Systemerweiterung und -anpassung durch Austausch oder Erneuerung von Filtern.
(3.4.) Steuerungsmuster
Steuerungsmuster definieren die Laufzeitdynamik eines Systems und werden primär in zentrale Steuerung und Ereignissteuerung unterteilt. Master-Slave-Modell (Zentral)
Dieses Modell regelt die Kommunikation durch eine klare Hierarchie: Eine zentrale Kontrollinstanz (Master) steuert ein oder mehrere passive Elemente (Slaves).
Zentrale Steuerung
Es gibt eine unidirektionale Kontrollrichtung; Slaves agieren nur auf Aufforderung. Dadurch werden Datenkollisionen und unberechtigte Ressourcenzugriffe durch einfache Verwaltung verhindert. .
Call-Return-Muster
Ein klassisches Strukturprinzip, bei dem ein Hauptprogramm Unterprogramme sequenziell aufruft und auf deren Rückmeldung wartet.
- Vorteil: Sehr einfache Implementierung und Übersichtlichkeit.
- Nachteil: Fehlende Parallelverarbeitung; schlechte Fehlertoleranz in Ausnahmesituationen, da das System blockiert wird.
Ereignissteuerung (Dezentral)
Im Gegensatz zu zentralen Modellen basiert die Steuerung hier auf dem Eintreten spezifischer Ereignisse (Events). Bekannte Formen sind der Selective Broadcast (Nachrichten an interessierte Empfänger) oder Interrupts (Hardware-Signale, die den normalen Programmfluss unterbrechen).
Ereignissteuerung (Event-Driven Control)
Die Ereignissteuerung regelt die Systemdynamik über asynchrone oder synchrone Impulse und differenziert dabei primär zwischen dem Selective Broadcast und dem Interrupt-Muster.
Beim Interrupt-Verfahren werden vordefinierte Ereignisse über einen Handler gezielt und synchron an zuständige Subsysteme geleitet, wobei die aktuelle Prozessausführung zugunsten einer sofortigen Befehlsabarbeitung unterbrochen wird. Ein klassisches Anwendungsbeispiel ist die Hardwaresteuerung über Eingabegeräte wie Maus oder Tastatur, bei denen spezifische Signalleitungen und Speicheradressen eine schnelle Reaktion garantieren. Im Vergleich zum Polling, der zyklischen Abfrage aller Komponenten, bietet der Interrupt einen deutlichen Geschwindigkeitsvorteil, erkauft dies jedoch mit einer komplexeren Testbarkeit der Software.
Im Gegensatz dazu realisiert der Selective Broadcast einen asynchronen Nachrichtenversand an eine unbestimmte Anzahl von Empfängern. Ein zentraler Event Handler verteilt Ereignisse an alle Subsysteme, ohne eine Rückmeldung abzuwarten, was die Kopplung zwischen den Komponenten minimiert und die Erweiterbarkeit des Systems erheblich erleichtert. Da die Subsysteme eigenständig über die Relevanz eines Ereignisses entscheiden und keine zentrale Abstimmung erfolgt, liegt der Nachteil dieses Musters in potenziellen Konflikten, wenn mehrere Komponenten konkurrierend auf denselben Impuls reagieren.
Adaption
Das Adaptionsmuster nutzt verschiedene Techniken zur Steigerung der Softwareflexibilität, wobei die Dependency Injection (DI) eine zentrale Rolle spielt. Bei diesem Verfahren wird die Verantwortung für die Erzeugung und Vernetzung von Objekten aus den einzelnen Klassen herausgelöst und in eine zentrale Komponente oder ein Framework verlagert. Da die Objekte ihre benötigten Ressourcen nicht mehr selbst verwalten, wird der Objektcode unabhängig von seiner Umgebung, was die Kopplung verringert und die Durchführung von Komponenten- und Modultests erheblich vereinfacht.
Ein weiterer Aspekt der Adaption ist die Reflexion, welche den Zugriff auf Metainformationen von Komponenten während der Laufzeit ermöglicht und somit eine dynamische Systemanpassung erlaubt.
In der Praxis lassen sich diese Adaptionsmuster effektiv mit anderen Strukturen kombinieren, beispielsweise indem Server innerhalb einer Client-Server-Architektur zusätzlich in funktionalen Schichten konfiguriert werden, um sowohl Flexibilität als auch Ordnung zu gewährleisten.
(3.5.) Verteilung
Die Verteilung beschreibt die Aufgabenverteilung auf verschiedene Komponenten. Die Verteilungsmuster beschreiben die Verteilungssicht bzw. physische Sicht. Client-Server-Systeme, Peer-to-Peer-Systeme und Service-Oriented Architecture sind Beispiele von Verteilungsmuster.
(3.5.1.) Funktionale Verteilung in der Architekturgestaltung (Verteilungsmuster)
Architekturen mit funktionaler Spezialisierung basieren auf der Zuweisung spezifischer Funktionen an dedizierte Prozessoren oder Rechner, was zu einer klaren funktionalen Trennung der Hardware führt. Diese Verteilung verursacht zwar einen erhöhten Kommunikationsaufwand zwischen den Einheiten und birgt Risiken wie Engpässe bei spezialisierten Komponenten, eingeschränkte Möglichkeiten zur Lastverteilung sowie Verfügbarkeitsprobleme bei Ausfall eines spezialisierten Knotens. Dennoch ist dieses Vorgehen in der Praxis weit verbreitet und sinnvoll, da es eine effektive Partitionierung und Replikation von Teilfunktionen ermöglicht. Um die genannten Nachteile abzufedern, setzen moderne Architekturen häufig auf Mischformen, die Elemente der funktionalen Spezialisierung mit denen der funktionalen Gleichstellung kombinieren.
(3.5.1.1) Client-Server-Systeme
Das Client-Server-System basiert auf einer klaren Trennung zwischen dienstleistenden Servern und dienstkonsumierenden Clients, die typischerweise auf getrennter Hardware laufen und über einen nachrichtenbasierten Anfrage-Antwort-Mechanismus miteinander kommunizieren. Hinsichtlich der Verteilung der Rechenlast wird zwischen Thin Clients und Fat Clients unterschieden, wobei Thin Clients lediglich als Anzeigeterminals fungieren und die gesamte Verarbeitungslast dem Server überlassen, was leistungsstarke zentrale Hardware erfordert. Im Gegensatz dazu führen Fat Clients wesentliche Teile der Fachlogik lokal aus, wodurch der Server entlastet wird und sich primär auf die Datenhaltung beschränken kann, was zudem die Ausfallsicherheit des Gesamtsystems erhöht. Als fundamentales Architekturmuster des Internets bildet dieses Modell die technische Basis für essenzielle Dienste und Protokolle in TCP/IP-Netzwerken, darunter der Webseitenabruf via HTTP, der E-Mail-Verkehr sowie Datentransfers und Namensauflösungen.
(3.5.1.2) P2P-Systeme
Bei dieser Struktur herrscht Gleichberechtigung zwischen den Komponenten, die meist über Nachrichten kommunizieren. Jeder Peer kann dieselben Funktionen ausführen. Sie können sowohl Dienste anbieten als auch in Anspruch nehmen. Das World Wide Web ist ein Peer-to-Peer-Netzwerk von Internetservern. Neben dem Einsatz auf Musikaustauschbörsen wird das Peer-to-Peer-System häufig bei der parallelen Programmierung im Bereich des High-Performance-Computing verwendet. Weitere Anwendungsbereiche dieses Modells sind Grid Computing (verteiltes Computing) und Filesharing-Services im Internet.
(3.5.1.3) Serviceorientierte Architektur (SOA)
Die serviceorientierte Architektur besteht aus lose gekoppelten Web Services. Diese Web Services kapseln fachliche Funktionalitäten. Dienste mit niedrigem Abstraktionsniveau können zu Diensten mit höherem Abstraktionsniveau kombiniert werden. Sie können flexibel zu Geschäftsprozessen zusammengesetzt werden. Diese sogenannte Orchestrierung übernimmt eine Orchestrierungskomponente. Damit für jeden Zweck der passendste Web Service gewählt werden kann, benötigen sie eine möglichst maschinenlesbare Schnittstellen- und Funktionsbeschreibung in der XML-basierten Sprache Web Service Description Language (WSDL). Diese Beschreibung wird auch gerade dann benötigt, wenn der Serviceverwender („Service Consumer“) einen Web Service bei einem anderen Unternehmen (Service Provider) einkauft oder mietet. Die Vermittlung übernimmt oft ein Service Broker, der die Web Services in einem Web Service Repository verwaltet.
(3.5.2.) Arten der parallelen Datenverarbeitung
Im Bereich der parallelen Datenverarbeitung wird grundlegend zwischen Inter- und Intra-Transaktionsparallelität unterschieden, um Aufgaben effizient auf Komponenten zu verteilen.
Die Inter-Transaktionsparallelität bezeichnet die gleichzeitige Verarbeitung verschiedener, unabhängiger Transaktionen unterschiedlicher Benutzer, was bereits bei herkömmlichen zentralen Datenbanksystemen im Mehrbenutzerbetrieb den Standard darstellt.
Die eigentliche technologische Besonderheit liegt jedoch in der Intra-Transaktionsparallelität, bei der die Operationen innerhalb einer einzigen Transaktion parallel ausgeführt werden, was die Antwortzeiten bei komplexen Abfragen und sehr großen Datenmengen drastisch reduziert.
(3.5.2.1.) Inter-Query-Parallelität
Die Inter-Query-Parallelität beschreibt die gleichzeitige Bearbeitung verschiedener Datenbankoperationen innerhalb derselben Transaktion, wobei der tatsächliche Geschwindigkeitsgewinn durch logische Abhängigkeiten der Teilschritte voneinander begrenzt wird. Da relationale Datenbanksysteme mit mengenorientierten Sprachen wie SQL arbeiten, ist zudem eine Parallelisierung innerhalb einer einzelnen Datenbankoperation möglich, die als Intra-Query-Parallelität bezeichnet und vollautomatisch vom Managementsystem gesteuert wird. Diese lässt sich weiter differenzieren in die Inter-Operatorparallelität, bei der verschiedene Basisoperationen wie Selektion und Projektion gemäß eines Operatorbaums gleichzeitig ablaufen, und die Intra-Operatorparallelität, bei der ein einziger rechenintensiver Basisoperator auf mehrere Ressourcen verteilt parallel ausgeführt wird.
(3.5.2.2.) Klassifikationskriterien
Verteilte Architekturen lassen sich zur Datenverwaltung anhand von fünf zentralen Merkmalen klassifizieren.
- Zunächst wird zwischen funktionaler Gleichstellung, bei der alle Prozessoren identische Aufgaben übernehmen, und funktionaler Spezialisierung unterschieden, bei der eine dedizierte Arbeitsteilung der Datenbankfunktionen stattfindet. - Ein weiteres wesentliches Kriterium ist die Speicherzuordnung, die entweder als gemeinsamer Zugriff aller Einheiten auf den gesamten externen Speicher oder als partitionierte Zuordnung mit exklusiven Datenbereichen für jeden Rechner erfolgt. - Hinsichtlich der räumlichen Dimension differenziert man zwischen lokalen Systemen, die durch unmittelbare Nachbarschaft hohe Übertragungsgeschwindigkeiten und Ausfallsicherheit bieten, und geografisch verteilten Systemen.
- Eng damit verknüpft ist die Art der technischen Kopplung, die von der engen Kopplung über einen gemeinsamen Hauptspeicher bis hin zur losen Kopplung mittels netzwerkbasiertem Nachrichtenaustausch reicht.
- Abschließend wird zwischen integrierten Systemen unterschieden, die logisch einen homogenen Datenbestand verwalten, und föderierten Ansätzen, welche mehrere ursprünglich unabhängige und heterogene Datenbanken zu einem Verbund zusammenfassen.
(3.5.2.3.) Klassen paralleler Datenbanksysteme: Shared Everything, Shared Disk vs. Shared Nothing
Basierend auf der Ressourcenteilung lassen sich parallele Datenbanksysteme in drei fundamentale Klassen unterteilen. Bei Shared-Everything-Systemen greifen alle Prozessoren eines Hochleistungsrechners gemeinsam auf den Haupt- und Externspeicher zu, was die Realisierung vereinfacht, die Skalierbarkeit jedoch durch die physikalischen Grenzen der Einzelhardware limitiert.
Im Gegensatz dazu basiert der Shared-Nothing-Ansatz auf einer vollständigen Trennung, bei der jeder Knoten über eigene Speicherressourcen verfügt und lediglich über ein Netzwerk kommuniziert, was eine enorme Skalierbarkeit auch mit Standardhardware ermöglicht, jedoch hohe Anforderungen an die Synchronisation stellt.
Als Mittelweg fungieren Shared-Disk-Systeme, bei denen die Verarbeitung zwar auf separaten Rechnerknoten stattfindet, diese jedoch auf einen zentralen Datenbestand zugreifen.
In der Praxis werden diese Ansätze häufig zu hybriden Architekturen kombiniert, indem beispielsweise einzelne Knoten eines Shared-Nothing-Clusters intern als Shared-Everything-Multiprozessoren aufgebaut sind oder geografisch verteilte Rechenzentren mittels Geo-Replikation vernetzt werden.
Technische Herausforderungen
In Shared-Disk-Systemen erzwingt der gemeinsame Zugriff aller Rechner auf den externen Speicher eine systemweite Synchronisation der Lese- und Schreibvorgänge, um die Serialisierbarkeit von Transaktionen sicherzustellen. Während dies bei loser Kopplung durch den notwendigen Nachrichtenaustausch oft zu spürbaren Kommunikationsverzögerungen führt, ermöglichen nah gekoppelte Systeme effizientere Mechanismen wie etwa eine globale Sperrtabelle in einem gemeinsamen Speicherbereich. Neben der Synchronisation stellen auch Logging, Recovery und Lastbalancierung hohe technische Anforderungen an diese Architektur.
Im Gegensatz dazu erfordert der Shared-Nothing-Ansatz aufgrund der strikten Datenpartitionierung spezialisierte Strategien, da jeder Knoten physisch nur auf seine lokalen Daten zugreifen kann. Dies bedingt komplexe verteilte Ausführungspläne für Datenbankoperationen sowie die Implementierung eines rechnerübergreifenden Commit-Protokolls, um die Atomarität (Alles-oder-nichts-Eigenschaft) verteilter Transaktionen zu garantieren. Zusätzliche Komplexität entsteht durch die Verwaltung globaler Katalogdaten, die Auflösung von Deadlocks zwischen den Knoten sowie die Konsistenzsicherung bei replizierten Datenbeständen.
(3.5.2.4) Virtualisierung und Cloud
Eine Cloud definiert sich als leistungsfähiger Verbund von Standardrechnern, der durch Virtualisierungstechnologie aus Anwendersicht wie ein einziges, virtuelles System agiert. Diese Technologie ermöglicht die Simulation von Servern, Betriebssystemen oder Speichermedien, was signifikante Vorteile wie Hardware-Reduzierung, vereinfachte Notfallwiederherstellung mittels Snapshots und eine effiziente Testumgebung bietet.
Dem stehen jedoch Hürden wie hohe Investitions- und Lizenzkosten, ein erheblicher Umstellungsaufwand, notwendige Schulungen sowie spezifische Sicherheitsrisiken gegenüber.
Ein zentrales Merkmal der Cloud ist die dynamische Zuweisung von Ressourcen, die eine beliebige Skalierbarkeit des Speicherplatzes und eine exakte Abrechnung nach dem Pay-per-Use-Modell erlaubt. Dies macht den Ansatz besonders attraktiv für Big-Data-Anwendungen, da teure Vorabinvestitionen in Spezialhardware entfallen und stattdessen skalierbare Standardhardware genutzt wird. Je nach Verwaltungstiefe werden drei Servicemodelle unterschieden: Infrastructure as a Service (IaaS) stellt virtuelle Hardware bereit, Platform as a Service (PaaS) bietet zusätzlich Laufzeitumgebungen für Entwickler, und Software as a Service (SaaS) liefert nutzungsfertige Anwendungen. Die Qualität dieser Dienste wird vertraglich über Service Level Agreements (SLA) geregelt, wobei Unternehmen für sensiblere Daten auch eine Private Cloud im eigenen Rechenzentrum betreiben können.
(3.6.) Modellgetriebene Architektur (Model Driven Architecture bzw. Model Driven Development)
Die modellgetriebene Architektur (MDA) beziehungsweise das Model Driven Development (MDD) markiert eine Abkehr von der traditionellen Softwareentwicklung, indem Modelle nicht mehr nur zur Analyse oder Dokumentation dienen, sondern als zentrales Fundament für die Generierung des fertigen Endprodukts fungieren. Das Kernziel dieses Ansatzes ist die Reduktion der Systemkomplexität durch Abstraktion: Programmiersprachenspezifische Details werden ausgeblendet, sodass sich Entwickler auf die fachliche Domäne konzentrieren können. Aus diesen abstrakten Modellen wird anschließend automatisch lauffähiger Code erzeugt, was nicht nur den manuellen Programmieraufwand und die damit verbundenen Kosten senkt, sondern auch die Softwarequalität durch die Vermeidung von Flüchtigkeitsfehlern maßgeblich steigert.
Strukturell basiert die MDA auf einer dreistufigen Hierarchie, die ein striktes Ordnungssystem vorgibt. Auf der untersten Ebene befindet sich das konkrete Modell der Anwendung. Darüber steht das Metamodell, welches die Syntax, die erlaubten Elemente und deren Beziehungen untereinander definiert - es ist sozusagen die "Grammatik" des Modells. Die oberste Abstraktionsebene bildet das Meta-Metamodell. Um diese theoretischen Konzepte in die Praxis umzusetzen, werden spezialisierte Softwarewerkzeuge genutzt, die Transformationen durchführen können. Ein typischer Workflow ist dabei die Umwandlung eines rein fachlichen, plattformunabhängigen Modells in ein technisches, plattformspezifisches Modell. Für den Austausch zwischen verschiedenen Tools hat sich das Format XMI etabliert.
Ein wesentlicher Aspekt bei der Werkzeugwahl ist der Unterschied zwischen grafischen und textuellen Modellierungsansätzen. Während grafische Standards wie UML oft sehr komplex sind, haben sich textuelle, domänenspezifische Sprachen (DSLs) als besonders effizient erwiesen. Sie verbessern die Kommunikation zwischen Fachabteilung und IT durch eine maßgeschneiderte Terminologie und bieten technisch den Vorteil, dass textuelle Modelle mit denselben Standard-Tools versioniert und verwaltet werden können wie klassischer Quellcode. Abschließend fügt sich die MDA in das Gesamtbild der Softwarearchitektur ein, indem sie bestehende Muster ergänzt. Die generierten Systeme basieren weiterhin auf bewährten Strukturen wie der Schichtenarchitektur, Verteilungsmustern wie Client-Server oder Peer-to-Peer sowie modernen Infrastrukturen wie der Cloud, bei der Virtualisierung und Skalierbarkeit im Vordergrund stehen.